|


|
|

| |||||||||||||||||||||||||||||||||||||||||||||||||||||||


記事=www.cio.com/article
投稿者=Allen Bernard, Managing Director @ CIOUpdate.com
投稿日=12/6/2012
最近のビッグデータ関連のニュースは多く、特にインメモリ(In-Memory)分析や、インメモリ技術、という言葉と連携して使われるケースが多い。昨今のサーバ仮想化の技術や、クラウド技術というのは、考えようによってはメインフレームから培われた仮想化の技術の発展系であって、本質的に時代を変えていく技術として注目されているのは、格段に安くなったDRAMを利用しインメモリ技術を利用したビッグデータ事業である、と言える
予測分析技術に特化したオープンソース言語である、Rの開発者である、Revolution Analytics社のDavid Smith氏は下記のコメントを述べている。
"In-memory has been around a long, long time, but now that we have big data, it's only the availability of terabyte (TB) systems and massive parallel processing [that makes] in-memory more interesting."
「インメモリ技術はかなり前から存在してます。ただ、ビッグデータの登場によって、その技術とテラバイト級の大型並列処理システムの組み合わせがインメモリ技術を大きく成長させる事が出来る。」
SAP HANAや、Oracle Exalyticsの様な、ビッグデータを利用したデータ分析アプリケーションを一つのハードウェアシステムとして組み込んで提供するシステムが登場している。HANAに関しては、Amazon Web Service上でのサービスや、SAPのNetWeaverプラットホーム等でも提供されている。
一方では、データ分析事業のプロバイダーである、SAS , Cognos, Tableau, Jaspersoft社等は自社製品の性能向上を狙い、In-Memory型の製品バージョンを発表している。ただし、Terracotta社のGM、Gary Nakamura氏によると、どの製品も(自社製品も含め)、活用出来るメモリー量もハードウェアではなく、製品自体のソフトウェア的な限界があり、厳密に言うとIn-Memory型のソリューションではない、と厳しく指摘している。
「要は、一つのプラットホームのフラッシュメモリ上に、データ、さらにそのデータモデルも含めて搭載し、高速で処理する事が出来る、という事が出来るか否かである。」とOpera Solutions社のShawn Belvins氏が述べている。
ビジネス的な観点からも、リアルタイムで大量のデータからビジネス上の決断を促す情報を如何に早く見出すかが重要であり、そこにIn-Memory技術への期待が集まっている。
NewVantage Partners社のPaul Barth氏は、
「In-Memory分析は高速な検索機能によって実現する」
と述べている。特定の地域において、青い自動車に乗っている人の郵便番号等、いろいろな項目同士の関連性を検索機能を駆使する事によって発見する、という作業である。
こういった、関連性を引き出そうとした時に、様々な形でデータを抽出し、関連性を見出すべく比較、分析が行われる。とある条件でデータをディスクから引き出すたびに大量のデータのI/Oが生じ、これがシステム全体の遅延を有無。すべてIn-Memoryで処理する事によって、この遅延を削減する事がポイントである。
データ解析/分析を行う場合、特に企業で戦略的なデータBIを行う際には、母体デーアに対して、様々な角度から上記のデータ抽出検索、分析が繰り返される。回数が多ければ多い程、データ分析を行う時にのスピードの重要性が増してくる。
今日のビッグデータ分析は、上記のデータ処理によるディスカバリー業務である、と言える。ただし、ビッグデータにおいては対象となるデータ、レコードの数が膨大な量になる事、尚かつ、それを効率よく、高速に処理を行うためにはディスクを使わず、すべてメモリ上の処理で対処する事が必要になってくる。
Facebookにおいて、例えば写真をアップロードすると、ほぼ同時に顔にタグ情報が自動的についてくる機能がある。Facebookは写真がアップされると同時に、写真上の顔一つ一つに対して顔認証のアルゴリズムを走らせ、特徴点を抽出した小さなデータ(40MBの写真に対してタグは40B程度)を生成し記録する。このデータはシステム内の特定のエンジンに移され、顔の認証を行い、名前を特定する。その後は、関係するアカウントに「写真上であなたがタグされました」、とメッセージを発信する。
この一連の処理は、ビッグデータならではの規模で初めて実現する機能である。また、In-Memory分析があるからこそ、この処理を一分に数万回に処理する機能が実現する。大抵のプログラマーは、Javaの制限があるために、100MB以上のデータをIn-Memoryキャッシュに搭載する人は少ない。メモリ上のデータを増やそうとすると、Javaの仮想エンジンを色々とチューニングする必要が生じる。それによって、システムはさらに遅くなる事もある。
現在、In-Memory分析は、高トラフィックで、演算負荷の少ないアプリケーションに向いている。ただ、プラットホーム上に数TB規模のDRAMもしくはフラッシュメモリを確保出来るようになると、アプリケーションの可能性がぐっと高まってくる。IT業界において、こういった高度な分析ビジネスに対するニーズは確実に存在し、分析対象のデータも大量に生成されている中、それを実現するテクノロジーの進歩が待たれている状況である。
テクノロジーが先に登場し、業界があとからそれをビジネスに適用する、という従来のITの業界モデルと異なり、ビッグデータの業界は既に対象となるデータ、そしてそれを高度な分析に利用したい、というニーズが確実に存在する中、従来のSQL型のデータベースインフラから新しいNoSQL/Mapeduce型のインフラに移行しつつあるのが今日の姿である、と言える。ハードウェア的な制限(メモリのコスト、等)が急激に亡くなりつつある状況の中、上記のニーズに対応出来るテクノロジーが登場した瞬間に、急激に市場が立ち上がって成長する事も予測する事が出来る。この急激な波にうまく乗れるかどうかが、企業の成長の分かれ目になる可能性もある。
記事=www.cloudtweaks.com
投稿者=Cloudtweaks
投稿日=1/2/2013

デジタルユニバース、とはグローバルで人間はどれだけデータを今日まで蓄積しているのか、という統計。2005年にはわずか130エクサバイト(ギガバイトの10億倍)だったデータは、どんどん蓄積され、2012年には2,837エクサバイト、2015年には8,591エクサバイト、2020年には40,026エクサバイトになる見込み。
各年ごとのデータ量増加率は;
2005 è 2010 = 9.44倍(年率=1.57倍)
2010 è 2012 = 2.31倍(年率=1.52倍)
2012 è 2015 = 3.02倍(年率=1.45倍)
2015 è 2020 = 4.65倍(年率=1.36倍)
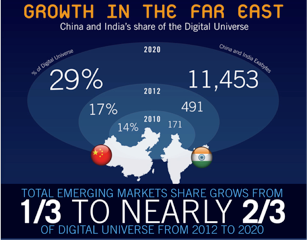
2020年までには、すべてのデジタル情報の29%が中国とインドで占められる、という予測。これは昨年の10%から比較すると大きな成長であり、年成長率、1.522倍に相当する。国レベルでデジタル化が進むと、人口が多いため、絶対量が急激に成長する、という現れである、と言える。

この図は、2012年に存在する2837エクサバイトのデータの内、実際に役に立つべく分析が行われているのは1%にも満たない、という事を示している。
分析する事によって価値が出てくる様々なデータの種類を分類すると、
監視カメラや監視装置、等の記録情報:44%
医療機器や内蔵機器等の情報:20%
データ処理機器からのデータ(ログ等):25%
娯楽関係やソーシャルメィア:10%
M2Mの領域に属するデータの量が非常に多く、分析もされず大量のデータが捨てられている、という状況が見える。
ビッグデータ技術に取っては、その機能を多いに発揮出来る分野である。

2012年のデジタル情報は、その多くが守られておらず、悪用される危険性をはらんでいる。特に経済発展国でのデータが守られていないケースが多く、情報セキュリティの徹底が必要となっている。

情報セキュリティ、といっても、保護をするべきレベルがいくつかあり、その情報の性格によって保護する手法を決める必要がある。全体の約半分がセキュリティを必要としている情報であり、その内訳は下記の通り:
プライバシーの保護を行う程度で十分な情報(YouTubeでのeメールアドレス等)=15%
コンプライアンス上、保護する事が法的に要求される情報(企業内のeメール等)=5%
ID情報等、成り済まし犯罪に利用される可能性のある情報=12%
機密情報、顧客リスト、等、持ち主等が機密情報として守りたい情報=6%
金融情報、需要な個人情報、医療情報、等非常に気密性の高い情報=6%

こういった大量のデータに対して、クラウドコンピューティングは非常に経済的に、かつ有効なストレージソリューションを提供する、という事がデジタル宇宙のデータの補完先の推移を見てわかる。2020年までにはかなりの量のデジタル情報がクラウド上で管理される事になる、という予測である。
逆に、クラウドコンピューティングが無いと、こういった大量のデータの管理が事実上不可能になる、という事も言える。

クラウド上で管理される情報の種類は、大量に保管出来る事だけではなく、多くは色んなデバイスからアクセス出来る、という利点も会って利用されるケースが多い。特に、エンターテイメント関連のデータ(映画、音楽、写真、等)は多くクラウド上で管理される事が今後多くなる事が予測されている。
また、地域別には、やはり総人口が絶対的に多い、中国、インド等での利用が非常に大きくなる事が予測されている。
これだけ、クラウド上での大規模データの管理/運用が多くなってくるとなると、それを管理/分析するデータベースエンジン、この場合はビッグデータ技術が中心になると考えられるが、さらにデータを利用するアプリケーションも、クラウド上で展開される方向になる事が多いに考えられる。これからのビッグデータのビジネスも、クラウド上で展開されるモデルが中心になる、という事が考えられるので、ビジネスもそのようなモデルで進める必要がある、と言える。